What is Site Reliability Engineering (SRE), and Why Should You Care?

By Monika Mueller
While it’s still a relatively new discipline, organizations are starting to recognize the strategic value of site reliability engineering (SRE). Though the term was coined by Google’s Ben Treynor Sloss back in 2003, the practice only truly emerged around 2016, when Google employed more than 1,000 site reliability engineers.
Led by cloud automation, the acceleration of digital transformation has boosted the adoption of SRE, but many organizations are still left wondering exactly what it is — and why they should care. We sat down with Jason Sandi, Softensity’s Lead Site Reliability Engineer, to get his perspective on this emerging discipline. It turns out, SRE is a lot like driving a car …
Ensure Reliability and Stability
Site reliability engineers bridge the gap between development and operations to monitor and support applications once they’re in production. According to Google, “It’s a mindset, and a set of practices, metrics, and prescriptive ways to ensure systems reliability.” Google quite literally wrote the book on SRE to provide tips on developing an SRE practice. In addition to ensuring reliability and stability, SREs support the security and scalability of an application.
Softensity’s Jason Sandi likes to explain SRE in non-technical terms that anyone can relate no to: it’s like driving a car. An SRE is like the driver of a car, who knows how the car is doing based on the dashboard data, from how much gas is left in the tank to the health of the engine. According to Jason, “the job of an SRE is being on top of those critical factors to make sure that the car keeps running.”
A Proactive Approach to Potential Issues
Production support’s job is to reactively address issues that have already occurred, and likely already had a negative impact on users. An SRE, on the other hand, proactively identifies — and prevents — issues before they happen.
Back to our car-and-driver analogy, it’s like a driver who’s on a road trip from California to Texas seeing that they only have 45 miles left on their current tank of gas. The driver will obviously make a quick and easy stop to get more gas before they run out. However, if no one is monitoring the gas needle, the driver won’t know they’re out of gas until the car stops. It then becomes a bigger issue that takes a lot more time and effort to resolve.
“The value of having a SRE is having a technical resource in your environment who is going to be looking at critical metrics for your application, and is going to be able to prevent issues before they even happen,” Jason explains. “SRE is about ensuring that your application is going to keep going 24/7 non-stop, as smoothly as possible. And preventing a lot of issues that users will never even realize were going to happen.”
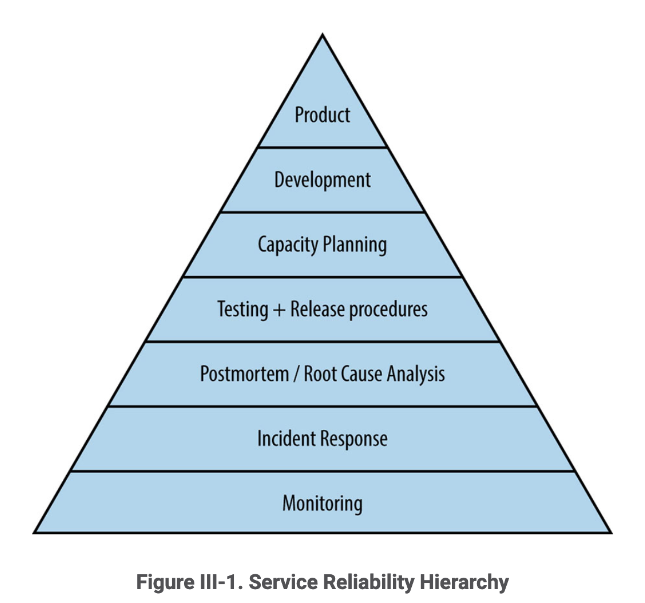
Source: “Site Reliability Engineering: How Google Runs Production Systems”
SREs Add Multiple Layers of Value
Preventing issues before they occur, and as Jason puts it “making a proactive effort to improve your application,” aren’t the only ways that SREs add value. Good SREs have development experience, which not only helps them resolve issues with speed and agility, but allows them to effectively collaborate with both the product and production support teams. SREs also work closely with DevOps engineers, focusing on implementation and automation that reduces incidents and improves reliability and scalability.
SREs add tremendous value through data collection and analysis. The engineers investigate and solve for recurring issues, then propose a permanent fix so the issue doesn’t happen again. Only about half of a site reliability engineer’s time is spent on operations. The other half of their time is spent on development tasks like creating new features, scaling the system and implementing automation. All of this input contributes to a robust application that works as expected, and is continuously improved.
What to Look for in Site Reliability Engineers
Beyond having development experience, SREs need to have a solid grasp on programming cycles and data structures. Experience with infrastructure management is also important — especially when it comes to troubleshooting cloud infrastructure. A good SRE will also possess soft skills, including everything from critical thinking and problem solving to communication. Beyond close collaboration with internal teams, SREs often interact directly with users and must be able to communicate effectively with them.
Oftentimes, organizations have highly complex apps that require around-the-clock support. In this case, partnering with a team that has SREs in different time zones can help you achieve 24/7 support.
Think your organization could benefit from site reliability engineering? Get in touch.











